
SpaceX dépose 80 milliards en IPO, Meta licencie 8000 en pleine course capex IA
Le brief IA #80


Anthropic
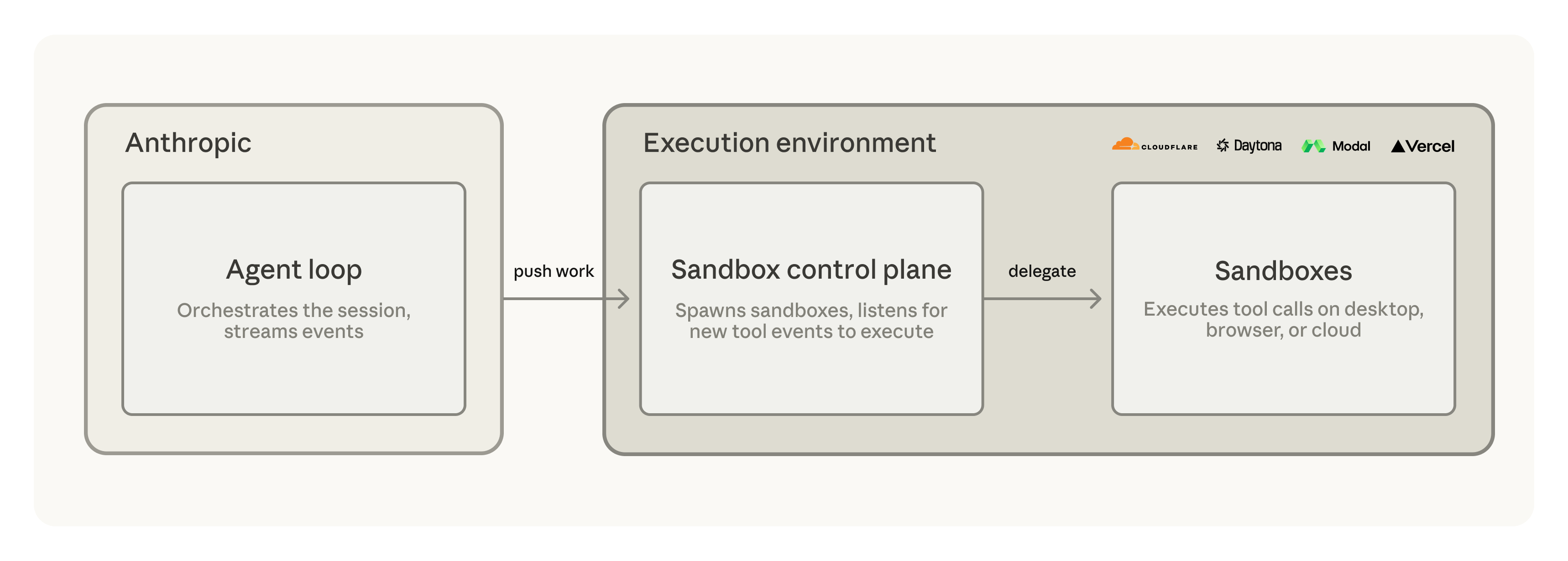
Anthropic isole Claude avec self-hosted sandboxes et MCP tunnels
Anthropic adresse enfin le blocage numéro un de Claude en entreprise : vos données quittaient leurs serveurs. Deux features en réponse. Les self-hosted sandboxes (public beta) laissent l’orchestration côté Anthropic mais déportent l’exécution code chez vous, ou via Cloudflare, Vercel, Modal. Les MCP tunnels (research preview) ouvrent une seule connexion sortante chiffrée pour accéder à vos bases internes, sans trou dans le firewall. Bonus : les outputs MCP au-delà de 100k tokens basculent automatiquement vers les fichiers du sandbox plutôt que de polluer le contexte.
Google
Google dévoile Gemini 3.5 Flash
À Google I/O d’il y a quelques jours, Google a annoncé basculer Gemini 3.5 Flash comme modèle par défaut dans l’app Gemini et dans le mode AI de Search, dans le monde entier. L’argument : performance agentique et coding au niveau flagship pour moins de la moitié du coût. Lancements couplés : Gemini Spark, agent personnel 24/7 qui tourne en background, et Omni, un world model qui édite ou génère de la vidéo à partir d’à peu près n’importe quel input. La stratégie : ne plus laisser le choix à l’utilisateur final, l’embarquer dans la stack Google par défaut.

Google enterre Gemini CLI et ouvre Antigravity en desktop + CLI + SDK
Google a sorti Antigravity 2.0, une app desktop perçue comme une réponse à Codex Desktop ou Claude Code Desktop. Côté modèle, Gemini 3.5 Flash mentionné dans la news précédente. L’app embarque aussi voice commands, accès Workspace, ponts Android et Firebase, export un-clic depuis AI Studio. Surtout, Google livre une nouvelle CLI Antigravity et un SDK pour construire ses propres agents par-dessus.
OpenAI
OpenAI dévoile Daybreak, plateforme cyber pilotée par GPT-5.5
OpenAI lance Daybreak, une plateforme de cyberdéfense IA qui bundle trois tiers de modèles : GPT-5.5 standard, GPT-5.5 Trusted Access for Cyber (secure code review, malware analysis), et GPT-5.5-Cyber pour red teaming et pentest sous accès strict. Au cœur, Codex Security ingère des repos entiers, construit un threat model spécifique à la codebase, mappe des chemins d’attaque réalistes, valide en sandbox isolé et propose des patches pour review humaine. Plus de 20 partenaires sécurité déjà branchés : CrowdStrike, Cloudflare, Palo Alto, Cisco, Trail of Bits.
xAI
xAI lance Grok Build, un CLI agentique enfin sérieux
xAI sort enfin sa réponse à Claude Code et Codex CLI : Grok Build, un agent qui vit dans le terminal. Plan Mode, sous-agents parallèles, fenêtre de contexte 2M tokens, mode headless -p pour intégration CI, extensible via Skills, hooks et MCP servers. Il lit même les CLAUDE.md existants sans modification. Le hic : Musk a publiquement reconnu que xAI était à la traîne sur le coding et le produit reste verrouillé derrière SuperGrok Heavy à 300 $/mois. Le ticket d’entrée est salé. xAI a perdu plus de 50 chercheurs depuis le rachat par SpaceX en février, donc on attend les retours utilisateurs avant de juger si l’outil tient la promesse.
Cohere
Cohere ouvre Command A+ en open-source pour l’entreprise
Cohere publie Command A+ en open-weight : un mixture-of-experts à 218 milliards de paramètres dont 25 milliards actifs. Le modèle tourne sur deux H100 ou un Blackwell, couvre 48 langues et ajoute du raisonnement multimodal. Le pari est clair : viser les boîtes qui veulent un frontier-like sans dépendre d’OpenAI ou Anthropic, et qui ont les GPU pour l’héberger. Cohere assume sa niche : pas la course aux benchmarks grand public, mais l’enterprise privée avec déploiement on-prem. Ça reste un modèle dont on entend peu parler.
Cursor
Cursor sort Composer 2.5 et joue la carte du modèle spécialisé
Cursor publie Composer 2.5, son modèle de coding maison, toujours bâti sur la base open-weight Kimi K2.5. Sur Terminal Bench 2.0 : 69.3, à côté d’Opus 4.7 (69.4). Le pricing change la donne : 0,07 $ par tâche en moyenne, contre 4,10 $ pour Opus et 4,82 $ pour GPT-5.5. Disponible uniquement dans l’IDE Cursor, pas d’API publique.


💰 SpaceX dépose la plus grosse IPO de l’histoire, à 80 milliards, en y consolidant les pertes de xAI
💸 OpenAI prépare son IPO confidentielle à plus de 1000 milliards de valorisation
🏭 Meta engage 145 milliards en capex IA et licencie 8000 personnes la même semaine
💼 Standard Chartered coupe 7000 postes en parlant officiellement de « lower-value human capital »
⚖️ Trump et Xi Jinping signent un protocole bilatéral de sécurité IA à Pékin
⛪ Le pape Léon XIV cosigne sa première encyclique IA avec Christopher Olah d’Anthropic

NVIDIA accélère DeepSeek Sparse Attention en exploitant la corrélation temporelle du Top-K
DeepSeek-V3.2 utilise du sparse attention : à chaque étape de décodage, le modèle sélectionne les K tokens les plus pertinents au lieu de tout attendre. Problème : recalculer ce Top-K à chaque step est coûteux. NVIDIA a regardé les données : entre deux steps consécutifs, 35 à 50% des indices Top-K se recouvrent, une corrélation temporelle qui sort directement de la structure Toeplitz de RoPE.
L’algorithme Guess-Verify-Refine part de là. À l’étape t+1, il devine le Top-K en reprenant celui de t, vérifie quels indices sont encore valides, puis ne refait le calcul que sur le delta. C’est exact (pas d’approximation), donc pas de perte de qualité.
Les chiffres en déploiement DeepSeek-V3.2 : 1,88× de speedup moyen sur les baselines déjà optimisées, jusqu’à 7,52% de réduction du time-per-output-token. Pour les équipes qui servent du sparse attention en production, c’est le genre d’optimisation qui se branche au niveau kernel sans toucher au modèle. La leçon plus large : il reste des gains à grappiller en regardant simplement ce que les tokens font d’un step à l’autre.
Six mois de LLMs résumés en cinq minutes par Simon Willison
Simon Willison a présenté un lightning talk à PyCon US 2026 qui essaie de couvrir tout ce qui s’est passé en LLM sur six mois en cinq minutes. C’est expéditif, factuel et c’est l’une des meilleures façons de se mettre à jour si on a décroché.
Le format : un slide par release marquante. En gros :
le décollage des coding agents (Codex, Claude Code, Cursor Composer, Grok Build).
L’arrivée des contextes à 1M+ tokens en standard.
La domination Anthropic en adoption business.
L’effondrement des coûts de la coding-task (Composer 2.5 à 0,07 $ vs 4 $ pour Opus).
Les world models qui passent de démo à prod (Gemini Omni, NVlabs SANA-WM).
Le talk se trouve sur le blog de Willison. À garder pour les sceptiques de votre équipe qui pensent encore que « rien n’a vraiment bougé depuis GPT-4 ». Le format synthèse cinq-minutes est probablement le meilleur ROI de la semaine pour qui doit présenter un état de l’art à son board ou à son équipe.

Tracer les coûts LLM comme un signal d’observabilité, pas comme une ligne de facture
Quand un système agentique consomme des tokens en continue (ou quasi), c’est évidemment une nouvelle dimension d’observabilité à monitorer. Le guide Comet ML rappelle qu’il faut sortir du raisonnement par modèle (« combien je dépense sur Claude ce mois ») pour passer au tracing par span, trace et projet : on veut savoir quel prompt précis brûle quel pourcentage du budget.
La structure recommandée : chaque tool call instrumenté avec ses tokens in/out, chaque trace agentique recomposée en arbre, chaque projet agrégé sur des dashboards.
Les LLM cost dashboards remplacent peu à peu les APM classiques pour les workflows IA. Comet, Langfuse, Opik (open source) et Phoenix se positionnent là. Pour les équipes qui déploient des agents en prod, c’est devenu un prérequis avant le go-live, pas une option qu’on branchera plus tard.
Redis Iris transforme Redis en context engine pour agents
Redis sort Iris, un context engine qui s’intercale entre les agents et les données enterprise. L’idée : packager dans une seule lib les outils dont a besoin un agent pour interroger vos systèmes avec une faible latence, des résultats à jour et un retrieval précis. Iris embarque deux nouveautés clés : Context Retriever (recherche hybride keyword + vecteurs + graphe) et Agent Memory (persistance multi-sessions).
Le chiffre (marketing) à retenir : avec semantic caching, Redis annonce jusqu’à 90% de réduction du coût en tokens sur les workloads RAG répétitifs. Concrètement, si vingt agents interrogent la même base de procédures internes en parallèle, le cache absorbe les requêtes proches et économise les round-trips vers le modèle.
Le pari de Redis est clair : ne pas laisser le retrieval agentique partir vers les vector DB spécialisées (Pinecone, Weaviate, Qdrant) sans se battre. Pour les équipes déjà sous Redis Enterprise, Iris s’active comme un module. Pour les autres, ça veut dire un nouveau composant à provisionner et opérer.
Construire un pipeline d’intelligence vidéo et audio multimodal avec Snowflake Cortex
Certaines entreprises accumulent des heures de vidéo et d’audio (calls clients, démos produit, conférences, contenu marketing) qui restent dormantes faute d’équipe pour monter un pipeline ML par-dessus. Snowflake Cortex (la couche IA du data warehouse Snowflake) propose un raccourci : appeler des LLM directement depuis SQL, sans jamais sortir la donnée du warehouse. L’article décortique un pipeline production qui orchestre AI_COMPLETE côté Snowflake, gemini-3.1-pro pour l’analyse vidéo, Claude Sonnet pour le post-processing texte, et sort du JSON structuré exploitable derrière. Cas d’usage couverts : sentiment de marque, product discovery, monitoring compliance FTC, content moderation.
Le design est SQL-first : chaque table sert d’étape, chaque vue matérialisée est un cache, l’incremental processing planifié évite de retraiter ce qui n’a pas bougé.
Point intéressant : router les sous-tâches vers le modèle le plus pertinent (vidéo vers Gemini, texte vers Claude) plutôt que de tout coller au même provider. C’est l’illustration concrète du « model routing » dont tout le monde parle. Les équipes qui structurent leur stack data autour de Snowflake gagnent un gros bloc multimodal sans avoir à monter une plateforme à part.

Emdash : un IDE agentique open-source pour piloter plusieurs coding agents en parallèle
L’Open-Source Agentic Development Environment. Vous lancez plusieurs coding agents en parallèle (Claude Code, Codex, Cursor Composer, Grok Build) sur le même repo. Le harness gère les permissions, les snapshots Git, le routing et la review unifiée des diffs. Compatible avec n’importe quel provider, donc bon candidat pour éviter le vendor lock-in.
Ml-intern : l’agent ML autonome de Hugging Face
Agent ML autonome qui lit les papiers, identifie les datasets, écrit le code d’entraînement et fine-tune les modèles. Démo qui fait du bruit : Qwen3-1.7B passé de 10% à 32% sur GPQA en 10 heures sur un seul H100, sans intervention humaine. Premier agent de cette ampleur sorti d’un acteur open source majeur. À regarder si vous automatisez les itérations de fine-tuning.

Less is More: Recursive Reasoning with Tiny Networks
Hierarchical Reasoning Model (HRM) is a novel approach using two small neural networks recursing at different frequencies. This biologically inspired method beats Large Language models (LLMs) on hard puzzle tasks such as Sudoku, Maze, and ARC-AGI while trained with small models (27M parameters) on small data (around 1000 examples). HRM holds great promise for solving hard problems with small networks, but it is not yet well understood and may be suboptimal. We propose Tiny Recursive Model (TRM), a much simpler recursive reasoning approach that achieves significantly higher generalization than HRM, while using a single tiny network with only 2 layers. With only 7M parameters, TRM obtains 45% test-accuracy on ARC-AGI-1 and 8% on ARC-AGI-2, higher than most LLMs (e.g., Deepseek R1, o3-mini, Gemini 2.5 Pro) with less than 0.01% of the parameters.